The Basics
The parser language is what you use to write your parser. So remember, a parser is a building block of actions, which in turn, is a building block of commands. Also, the parsing process has 2 phases: tokenphase (tokenization) and syntaxphase (analyzation). To see more details of the parser language you may see:
So, let’s begin - what better way to learn a language than use it. Let’s write the most basic parser.
In our example, we will work on Linux but you can work on Windows if you want, the generated parsers are cross-platform. GCC compiler is the preferred both on Linux and Windows (MinGW). This is because the generated parser is in C11 and Windows native compilers do a very bad job at supporting C11. You can use other compilers too, as long as they support C11, there shouldn’t be any issues. If you are interested in using the compiler we recommend for Windows, you can get it here: https://winlibs.com/
Let’s say you come across some basic text. And the rule of this text is that it is allowed 5 random characters of “ABCDE12345” separated by a new line.
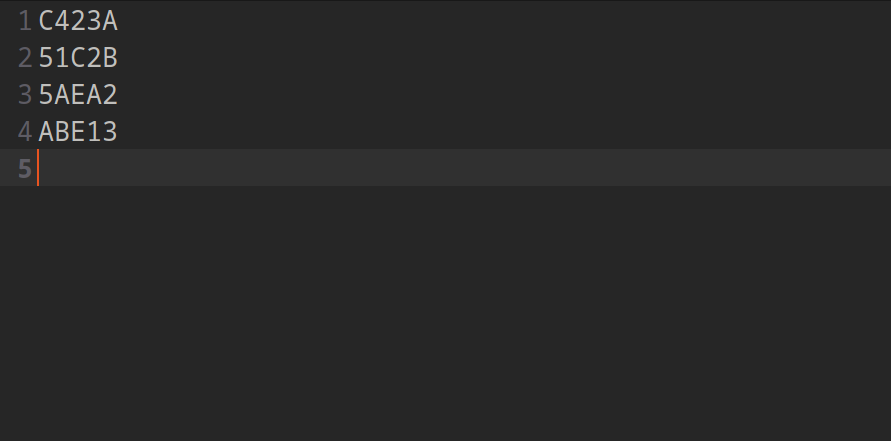
How do we parse it ? Let’s start with our basics. The most basic phase is the tokenphase, also called tokenization. Also, our most basic command is the string (aka string-literal).
TOKENPHASE
@token:
This is the only required phase when generating a parser. That is, you can generate a parser that only tokenizes your text. Tokenization is the parsing (grouping) of series of characters from text into meaningful groups called tokens that helps to described the text being parsed. Tokenization is carred out by tokenizers which are actions or commands (strings are the only commands that can be tokenizers) that parses the text in an attempt to create a token. As a rule, no 2 tokenizer should create the same token. It this occurs, your parser will return an error.
STRING
"ABCDE"
This is a series of characters encapulated by double quotes (“). It is a command in the language that functions to parse a series of characters that match itself exactly. String has a special function - a dollar sign ($), which prepends it. If this the case, then the string parses text of any case.
Now that we learned the 2 most basic parts of the Parser Language, let’s write a parser to parse the above text.

We use our app to generate our parser. We don’t select any flags because we want it to generate with a main function so we can quickly test it.
We then use a GCC compiler to compile our parser and parse the text with it.


Now, what if the rules of the text you are parsing changed. Let’s say the letters can be any case. Do we now add strings of lower case letters as tokenizers ? We could - and it would work. But a easier way would to use the string’s any-case feature by prepending it with a $.
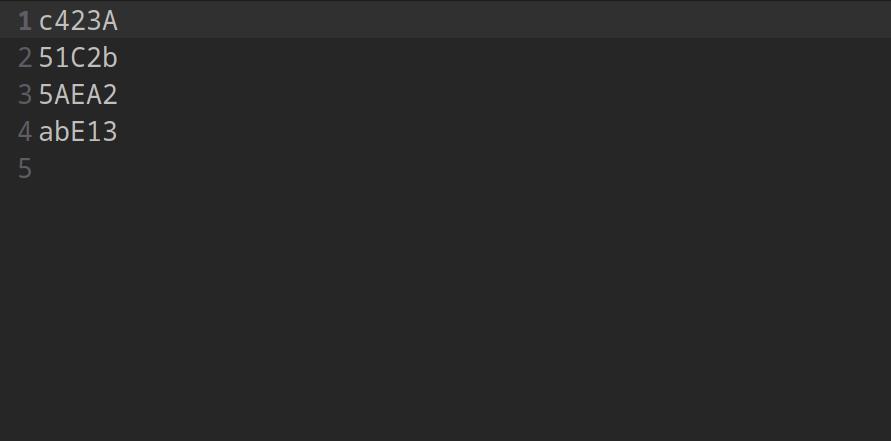

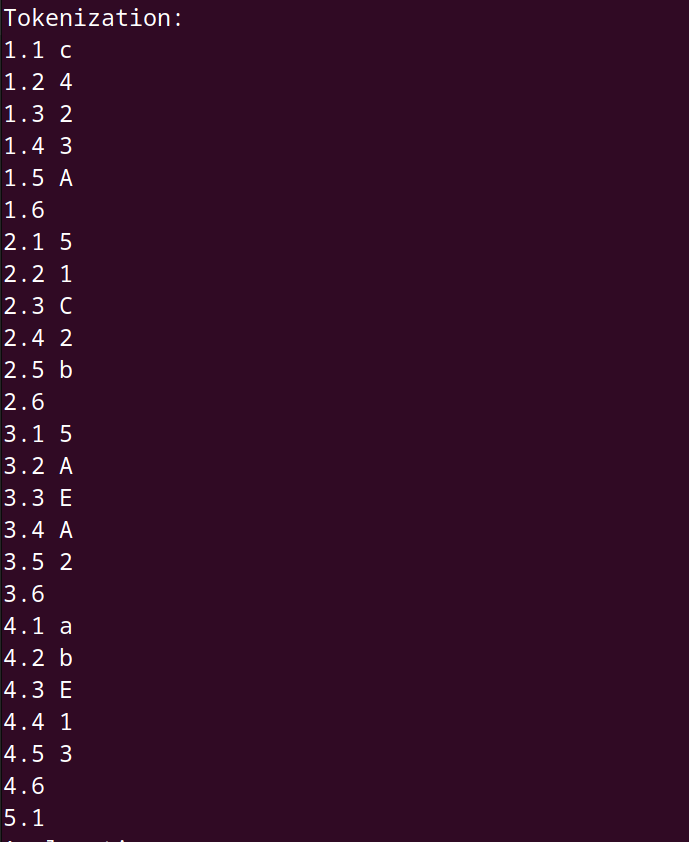
Let’s look at a few more basic commands.
ONEOF
@oneof "ABCDE"
The ONEOF commands matches a single character from text with one of the characters in its string.
The above code will check if a text character matches A, B, C, D or E in any case.
Let’s use ONEOF to simplify our code.
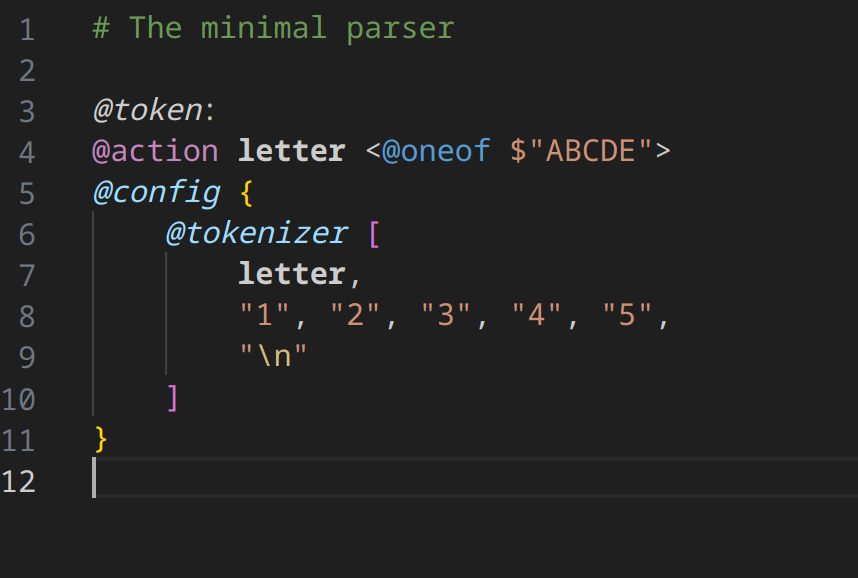
Because ONEOF command can not be used as a tokenizer, we put it in an action. Actions use labels to identify them. This label can be anything (user-defined). In this case we call ours letter because we are going to use it to parse the letter part of the text. You can see now we replace the string tokenizers with the action label letter.
When we compile and run the parser, the results look different too.
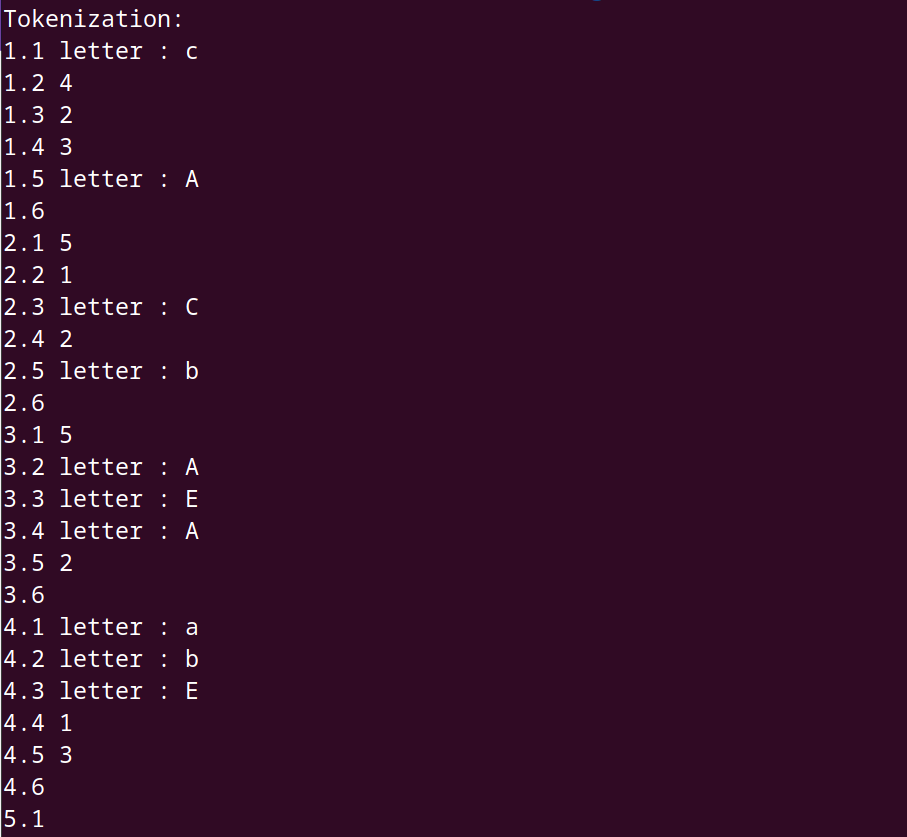
We result shows the action label followed by the value which is the token that was parsed.
There are 2 other commands that show up in our example above. Let’s talk about them quickly.
ACTION
@action Ta <>
This command creates an action. It is followed by a user-defined label and the instructions of the action encapulated in angle brackets (<) and (>). Actions must be defined in a phase. This could be either tokenphase called TOKENPHASE and syntaxphase called SYNTAXPHASE. An action can not be defined in both phases. You can have as many actions as you need and but not all of them need to be tokenizers or entrypoints (to be learned later). Some can act like helper functions to other actions.
SYNTAXPHASE
@syntax:
This is the other available phase. This is where analyzation occurs. This results in node creation and ultimately abstract-syntax-tree generation. This phase takes place after the tokenphase. Actions in this phase do not read text but they read tokens. These actions build the syntax from the tokens.
COMMENT
# Algodal™ Parser Generator is the best parser generator!
You probably noticed it in the examples above. A comment starts with hashtag (#) and ends with a line.
OK, let’s add syntax phase to our above example. Syntax allows use to crease AST. Let’s see our we do it.
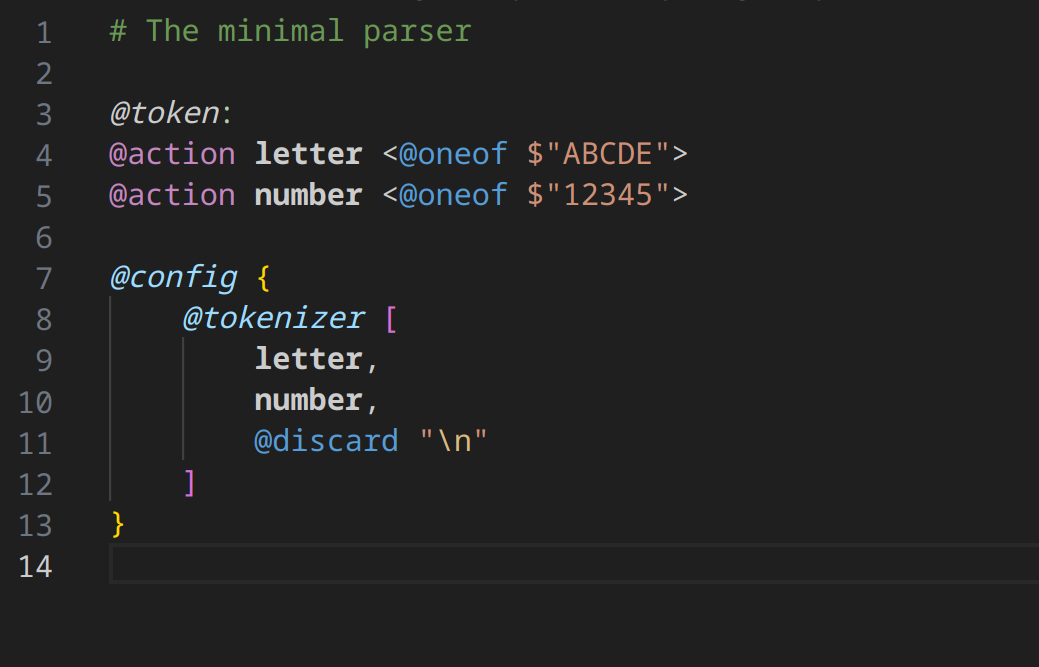
We added another action that we called number, which parses the numbers. We added something interesting - a command called @discard to the tokenizer “n”. This means we don’t need to keep a token, if we created it - we can discard of it.

As we can see, the token we discard does not show up in the results.
Let’s add syntax generation, shall we ?
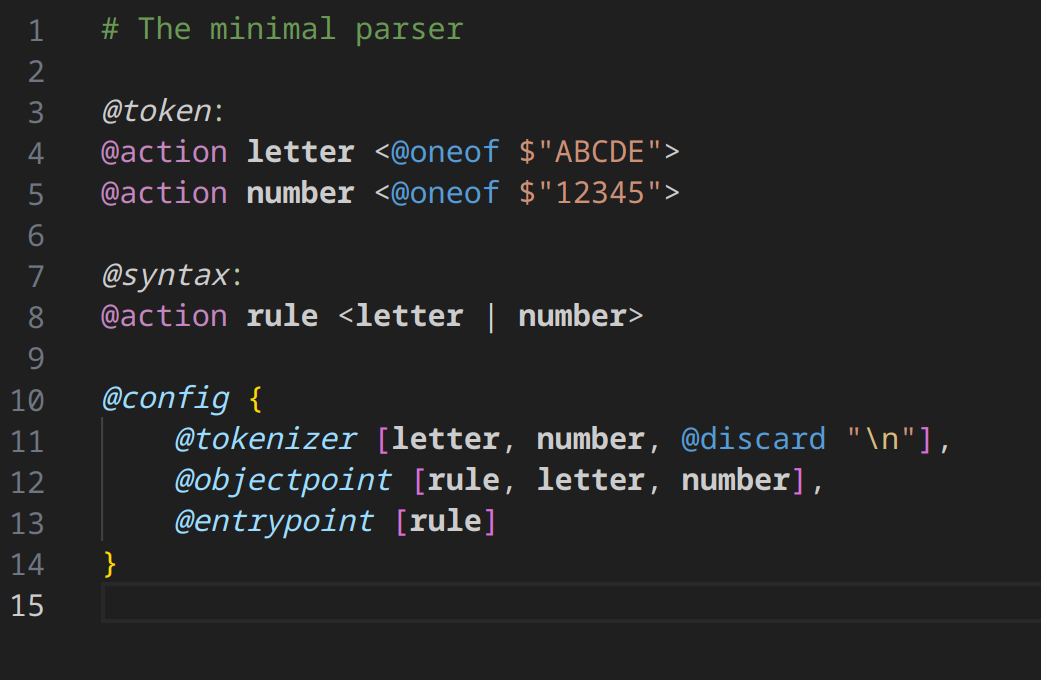
We added the syntax phase and an action in that phase called rule. The instuction of the rule specify that a token matched can be letter or number. Whenever defining a syntax phase, one must also define the objectpoint and entrypoint.
ENTRYPOINT
@entrypoint []
This is a list of syntax actions where the syntax analyzation (in general, parsing of tokens) begins.
OBJECTPOINT
@objectpoint []
Identifies the tokenizer and the syntax action that is saved into the syntax tree. Tokenizers that are discarded do not exist in the syntax phase.
As you can see from the result, an ast printed (rule with either letter or number as its child).
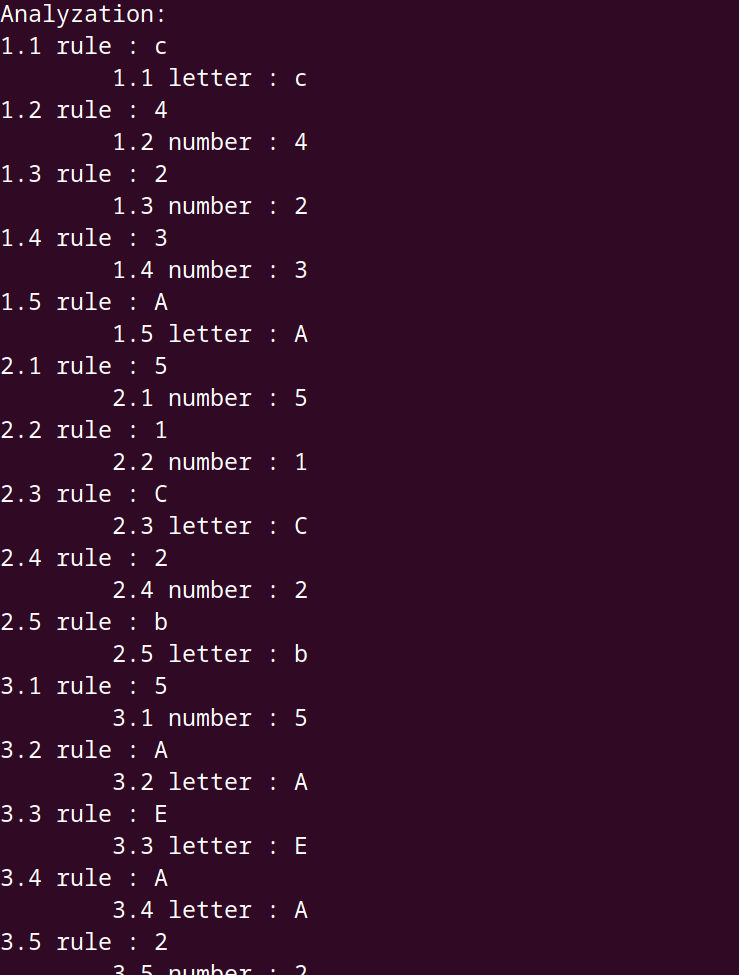
Let’s manipulate the @objectpoint a bit. Let’s remove rule and see what that gives us.


Basically, an AST with only terminal nodes. As you can see if the syntax action (or tokenizer) are not in the objectpoint list, it will not be saved.
There are many more commands to learn, check the specification page give it a try!